
Modernizing a DirectX real-time renderer - Multi-threading the VQEngine
Estimated Read Time: ~15 minutes
Table of Contents
- The Old DirectX11 Renderer
- The New DirectX12 Renderer
- Multi-threaded Architecture
- Event Handling
- Thread Synchronization
- Thread Pool
The Old DirectX11 Renderer
Nearly 4 years ago I started writing my own renderer VQEngine (Vanilla) to learn more about and get hands-on experience with real-time computer graphics. Working on my spare time, I did 6 point releases with various features and improvements along the way.
- Physically-based Rendering with GGX-Smith BRDFs
- Spot, Point & Directional lights with PCF shadows
- Screen-space Ambient Occlusion (SSAO)
- Environment Maps (Image-based lighting)
- Pixel & Compute Shader PostProcessing: Bloom & HDR Tonemapping
- Supersample Anti-aliasing
- 3D Asset loading with assimp
- LODs for built-in geometry (Spheres, cylinders, cones)
- Simple text rendering
- CPU & GPU profilers
- Instanced rendering, view frustum culling
- Automated Build & Logging
- Live shader editing
- Shader Reflection, Shader Cache & Shader Permutations
Even though the engine was written with DirectX11, I have almost excessively used learnopengl.com by Joey De Vries twitter as a reference to establish an understanding of various rendering techniques such as PBR, Shadow Mapping, Normal Mapping, etc. and figured the details out with DirectX11 along the way.
I believe the website is very well written and is probably the best resource out there for entry level graphics programming and it deserves a shout-out. It certainly helped me launch my career in computer graphics.
After 4 years of spare time development, I find the results quite fruitful for what I initially aimed for myself.






The New DirectX12 Renderer
Before I dive in to the details of the new VQEngine: VQE, I want to talk about my initial approach of adding DX12.
My initial strategy was to reuse as much code as I can from the DX11 renderer: I wanted to keep the abstraction of the Renderer and the Engine while applying necessary improvements along the way to allow for separating the DX11 and DX12 implementations of the same interface. That would allow me to easily change the underlying API without changing the client, scene management module, code. After a futile attempt, I quickly found out that working around the conflicting philosophies of the APIs in the name of abstraction would cause a great amount of headache and time.
| DirectX11 | DirectX12 |
|---|---|
| - high-level: hardware is abstracted away - mostly single-threaded - automatic resource management by GPU driver - automatic CPU/GPU sync by GPU driver - easy to use |
- low-level: closer to hardware - designed for multi-threading - manual resource management - manual synchronization - harder to use for beginners |

With the DX12 design, what used to be the responsibility of the GPU driver was mostly given to the graphics programmer to give better control over synchronization and memory management to allow capable developers to unleash more power from the hardware. The devs would achieve this by better utilizing the hardware than the driver’s generic approach as they would know best what their application bottleneck would be and optimize the engine for that specific bottleneck. After this realization, I took some time off the project to recharge a bit.
In the span of years, real-time ray tracing took off with Microsoft’s Ray Tracing API: DirectX Raytracing (DXR) and Microsoft recently announced DirectX12 Ultimate bringing new technologies like Mesh Shaders, Variable Rate Shading (VRS), and Sampler Feedback to the newer generation Desktop & Console GPUs.
In the (green) light of the exciting news, I decided it’s time to go back to building a renderer, a cutting-edge one this time around.
Hence, VQE was born with the following in mind:
- DirectX12 & DXR
- Multi-threaded architecture
- HDR Display support
- Multi-monitor & window management
- Multi-GPU
- Real-time & Offline ray tracing
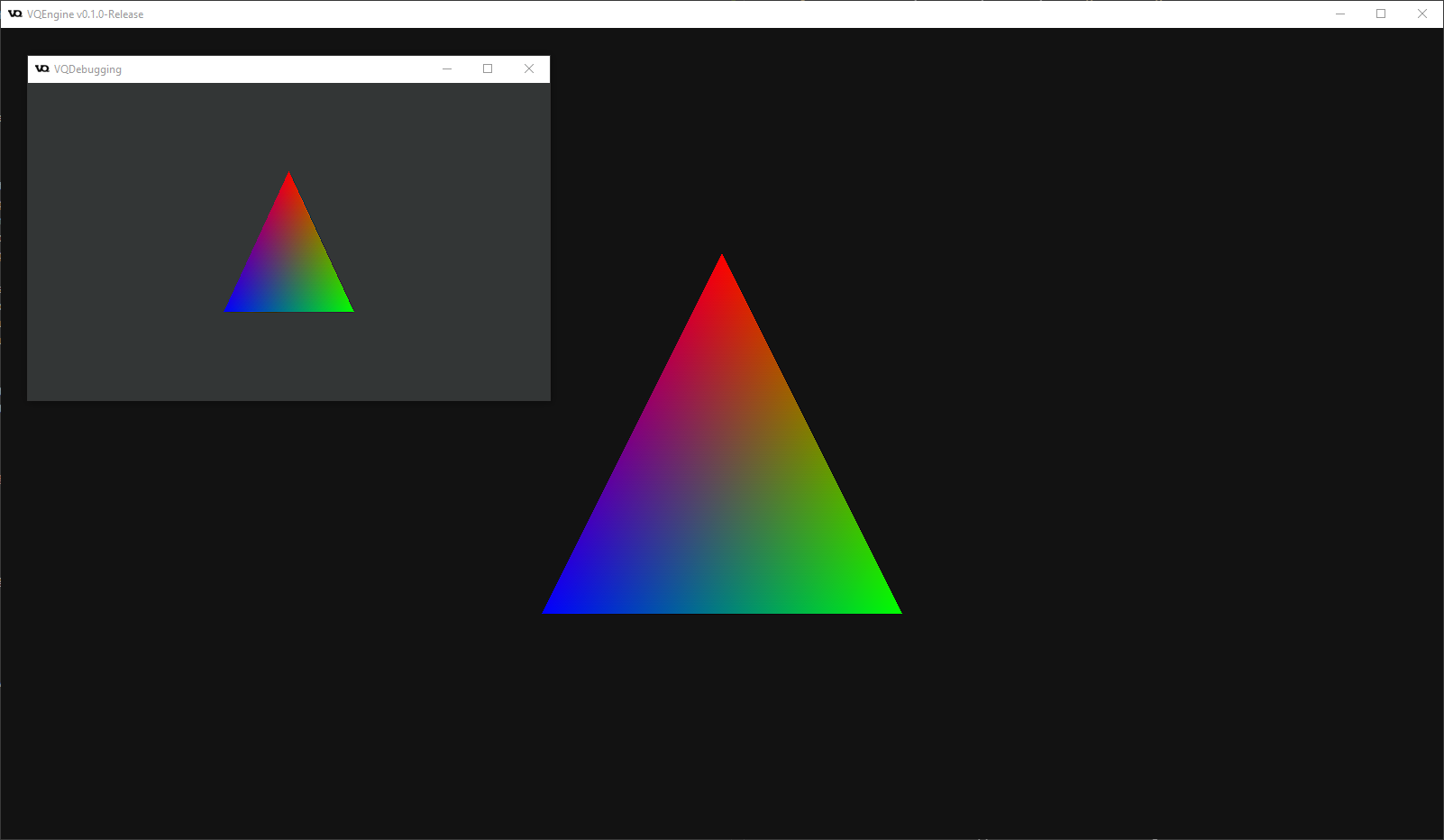
I have recently released the first build of the new VQEngine v0.1.0: Hello Triangle ! with the following features:
Multi-threading
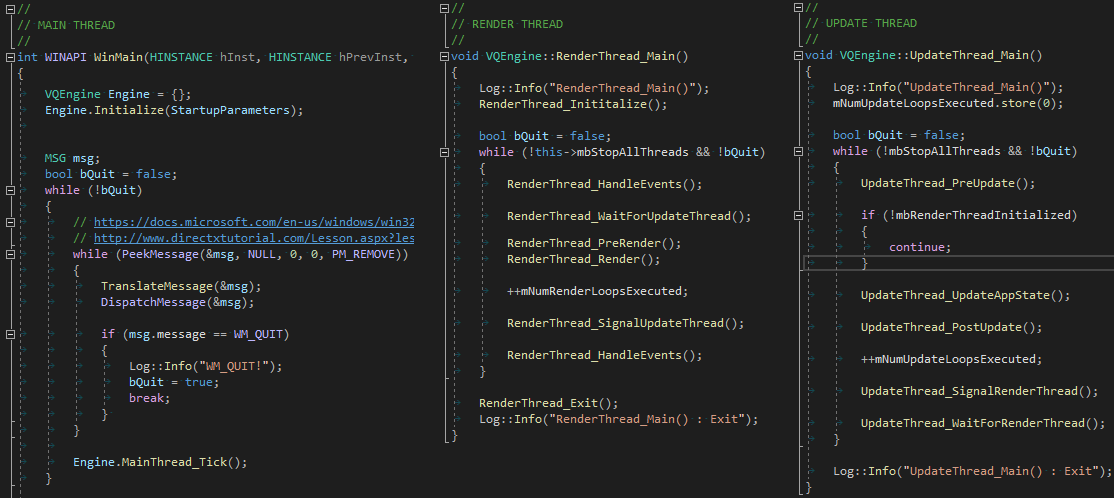
- 3 Independent threads
- Main Thread : Handles Windows events and buffers the events for consumption in other threads, ensuring seamless application behavior
- Update Thread : Simulates scene, prepares data for the Render Thread, doesn’t run ahead more frames than the back buffer has.
- Render Thread: Picks up scene data from the Update Thread and issues draw commands
- Thread Pools as worker threads for the Update and Render thread for parallelizing workloads, scaled by available threads on the system.
DXGI Window Management
- 3 Display Modes supported
- Windowed
- Borderless Fullscreen
- Exclusive Fullscreen
- Multiple windows supported on multiple monitors
- Alt+Enter Fullscreen transitions for both Borderless & Exclusive modes
D3D12 Rendering
- Hello World Triangle rendering with synchronized Update & Render threads
Utilities
- Logging to File and a separate Console window
- Command-line parameters
- Configurable settings through
.inifile- Set resolution
- Set preferred monitor
- Set fullscreen window
- Set Debug window properties (visible, resolution, fullscreen, preferred monitor)
Automated Build & Testing
PackageEngine.batto sync dependencies, generate project files, build in release mode and package the binaries for distributionGenerateProjectFiles.batto sync dependencies and generate project filesTestVQE.batto test runVQE.exefor a specified number of frames (1000 default)
Starting afresh was quite the relief compared to my earlier attempt at DX12. I felt so much strain on my design approach when I tried to keep the old interface while trying not to break things for the other API. Now, I can freely design interfaces and systems, and easily encapsulate data where necessary without such constraint.
With the fresh start, I really wanted to get multi-threading and the multi-display support going from the start and I’ll talk more about the details of both in the following sections.
Multi-threaded Architecture
For multi-threading, I’ve basically taken the Destiny’s Multithreaded Rendering Architecture by Natalya Tatarchuk as the base design. There’s also Multithreading the Entire Destiny Engine by Barry Genova for future ideas and a deeper dive on how jobifying is achieved in the Destiny’s engine.
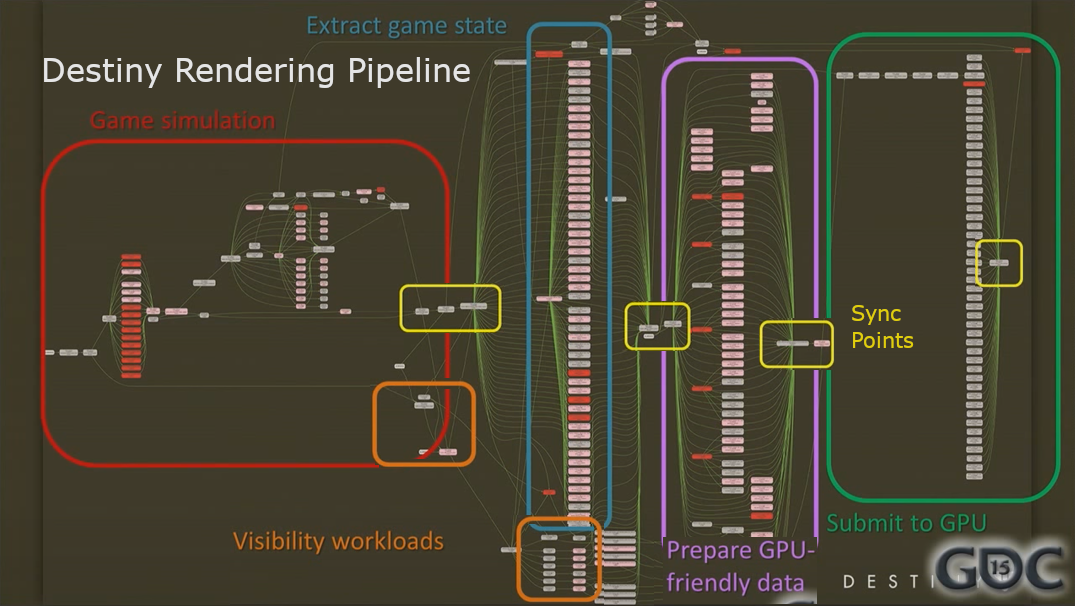
The design for Destiny’s data-driven rendering pipeline is as follows:
- An Update thread simulates the scene, runs the visibility tests and prepares the data for the Render thread while keeping mulitiple copies of the scene state for frame buffering
- A Render thread runs in sync with the Update thread, issuing draw commands for frame N while the Update thread is working on N+1
- Both Update and Render thread have a worker thread pool to utilize jobified tasks
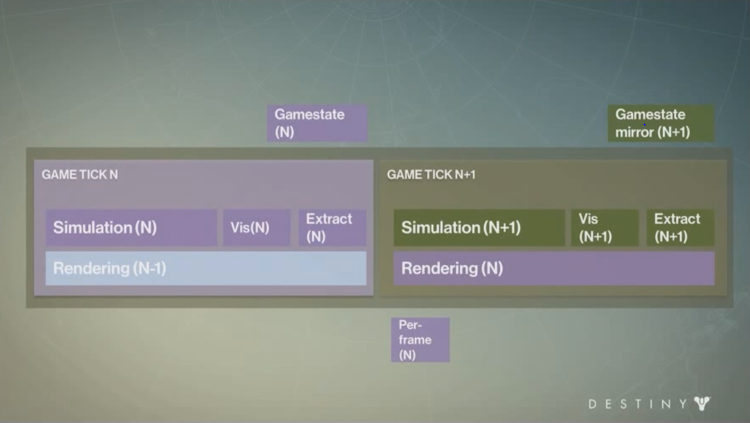
The main idea is to:
- Separate Update and Render data
- Delegate processing them to specific cores on the system
- Jobify as much tasks as possible to drive the multiple threads
- Use well defined sync points to avoid contention
For VQEngine, in addition to the architecture shown in Destiny presentations, I’ve added a Main Thread as the 3rd thread to handle Windows events to ensure application responsiveness even under heavy CPU/GPU workloads.
With this multi-threaded approach, I’ve had to deal with two problems that I didn’t have on single-threaded engine:
- Event Handling
- Thread Synchronization
Event Handling
Message handling (Main), Update and Render happening on separate threads means the events can occur in any order.
When everything was on the single thread, the
- Processing of Windows events
- Scene update
- Scene render
all happened in that order as the engine called Update() and Render() after the Peek/Translate/Dispatch message loop.
Now, handling a Window Resize event on the Main thread is not as straightforward as you also to resize the swapchain. This is a problem because the Render Thread could be in the middle of recording commands and the GPU could still be using the swapchain buffers when the Window Resize event occurs. The resize events should be processed either at the beginning or at the end of the frame to avoid this contention scenario.
Where there’s multi-threading, there usually are queues, both in software and hardware.
Hence, to solve this issue, the good old std::queue to the rescue along with some std::mutexes…
Wait, Mutexes is the right plural? Double checks stackoverflow…
Yep, mutexes sounds right… Mutices is a monster!
Anyway.
To handle the events in line with the requirements of the DXGI API for resizing window, resizing swapchain buffers & presenting, I’ve come up with the following solution:
A double buffered queue paired with a mutex is utilized to record events from the Main thread while the Render thread is processing the events prior to that point. This is similar to the double buffered swapchain presentation model where the GPU is drawing into one of the buffers while the display is showing the other buffer on the screen.
As some of you may already have realized, this is the classic producer-consumer problem!
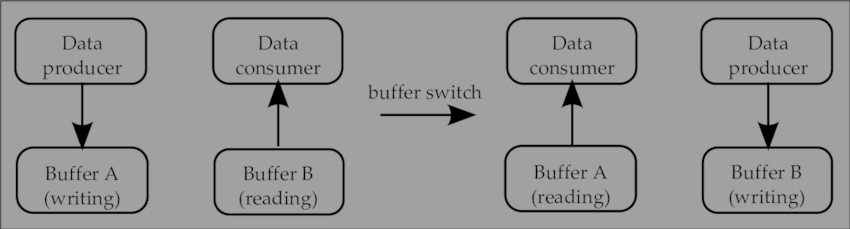
Source: ResearchGate, illustrating the idea of read and write happening on separate buffers with a switch/swap mechanism.
- Main thread records Window events to front queue
- To handle the events, Render Thread ‘flips’ the double-queue, and processes the recorded events thus far
- With the ‘flip’, Main thread now renders to the new ‘front queue’, allowing the Render Thread to safely process the events on the ‘back queue’
- Render thread handles events once before starting rendering a frame and once after presenting the swap buffer in order to properly handle the windows events
Below is my C++ implementation.
template<class TContainer, class TItem>
class BufferedContainer
{
public:
TContainer& GetBackContainer() { return mBufferPool[(iBuffer+1)%2]; }
const TContainer& GetBackContainer() const { return mBufferPool[(iBuffer+1)%2]; }
void AddItem(const TItem& item)
{
std::unique_lock<std::mutex> lk(mMtx);
mBufferPool[iBuffer].emplace(item);
}
void SwapBuffers()
{
std::unique_lock<std::mutex> lk(mMtx);
iBuffer ^= 1;
}
private:
mutable std::mutex mMtx;
std::array<TContainer, 2> mBufferPool;
int iBuffer = 0; // ping-pong index
};
// DOUBLE BUFFERED SHARED RESOURCE
BufferedContainer<std::queue<IEvent*>, IEvent*> mWinEventQueue;
// PRODUCER
void VQEngine::OnWindowResize(HWND hWnd)
{
// https://docs.microsoft.com/en-us/windows/win32/direct3ddxgi/d3d10-graphics-programming-guide-dxgi#handling-window-resizing
RECT clientRect = {};
GetClientRect(hWnd, &clientRect);
int w = clientRect.right - clientRect.left;
int h = clientRect.bottom - clientRect.top;
// Due to multi-threading, this thread will record the events and
// Render Thread will process the queue at the of a render loop
mWinEventQueue.AddItem(std::make_shared<WindowResizeEvent>(w, h, hWnd));
}
// CONSUMER
void VQEngine::RenderThread_HandleEvents()
{
// Swap event recording buffers so we can read & process a limited number of events safely.
// Otherwise, theoretically the producer (Main) thread could keep adding new events
// while we're spinning on the queue items below, and cause render thread to stall while, say, resizing.
mWinEventQueue.SwapBuffers();
std::queue<std::shared_ptr<IEvent>>& q = mWinEventQueue.GetBackContainer();
if (q.empty())
return;
// process the events
std::shared_ptr<IEvent> pEvent = nullptr;
std::shared_ptr<WindowResizeEvent> pResizeEvent = nullptr;
while (!q.empty())
{
pEvent = q.front();
q.pop();
switch (pEvent->mType)
{
case EEventType::WINDOW_RESIZE_EVENT:
// noop, we only care about the last RESIZE event to avoid calling SwapchainResize() unneccessarily
pResizeEvent = std::static_pointer_cast<WindowResizeEvent>(pEvent);
break;
case EEventType::TOGGLE_FULLSCREEN_EVENT:
// handle every fullscreen event
RenderThread_HandleToggleFullscreenEvent(pEvent.get());
break;
}
}
// Process Window Resize
if (pResizeEvent)
{
RenderThread_HandleResizeWindowEvent(pResizeEvent.get());
}
}In addition to solving the event handling problem, the double buffered approach also ensures a limited number of events are handled in a given frame.
Imagine the Main Thread pushing new events at the same time the Render Thread is handling the events: that would cause Render Thread to keep processing events if the Main Thread produces events fast enough and potentially cause a stall. Having separate Read/Write buffers leaves less room for unexpected edge cases.
With the event handling problem fixed, let’s look at thread synchronization.
Thread Synchronization
With separate Update and Render threads, work can be pipelined and done in parallel but both threads are expected to have varying workloads.
It must be ensured that
- Update Thread doesn’t get too ahead of the Render Thread - not more frames than
NumBackBuffers - Render Thread waits for Update Thread to have at least one frame processed before rendering
This can be achieved using two Semaphores.
For example, in a triple-buffered swapchain scenario
- Update Semaphore : Max Value 3, Starts At 3.
- Corresponds to the number of frames the Update Thread can process without waiting for Render Thread to finish rendering.
- Render Semaphore : Max Value 3, Starts At 0.
- Corresponds to the number of frames rendered
void VQEngine::InitializeThreads()
{
// Initialize Sync Objects
const int NUM_SWAPCHAIN_BACKBUFFERS = mSettings.gfx.bUseTripleBuffering ? 3 : 2;
mpSemUpdate.reset(new Semaphore(NUM_SWAPCHAIN_BACKBUFFERS, NUM_SWAPCHAIN_BACKBUFFERS));
mpSemRender.reset(new Semaphore(0 , NUM_SWAPCHAIN_BACKBUFFERS));
// Start Update & Render Threads
mbStopAllThreads.store(false);
mRenderThread = std::thread(&VQEngine::RenderThread_Main, this);
mUpdateThread = std::thread(&VQEngine::UpdateThread_Main, this);
// Initialize Worker Pools...
}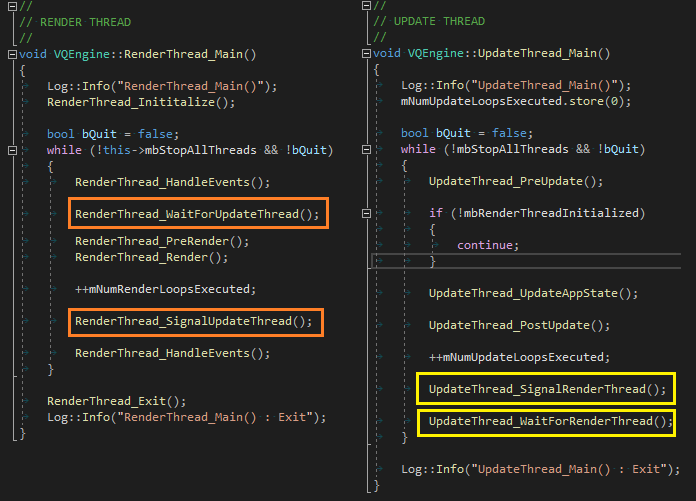
void VQEngine::UpdateThread_WaitForRenderThread() { mpSemUpdate->Wait(); }
void VQEngine::UpdateThread_SignalRenderThread() { mpSemRender->Signal(); }
void VQEngine::RenderThread_WaitForUpdateThread() { mpSemRender->Wait(); }
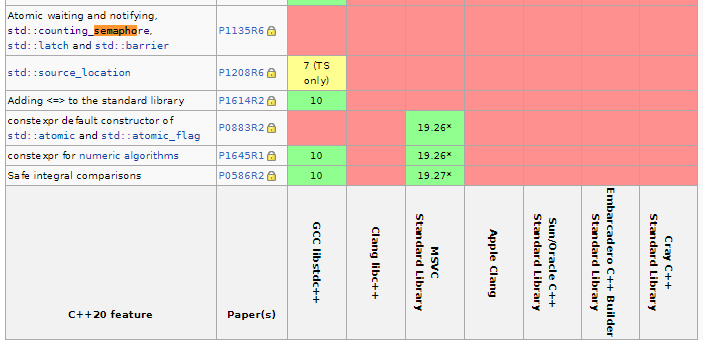
void VQEngine::RenderThread_SignalUpdateThread() { mpSemUpdate->Signal(); }For the Semaphore implementation, I’ve checked out the C++ standard library. Looks like the C++ people only recently decided to add std::counting_semaphore and std::binary_semaphore to the standard with C++20, nearly a decade after intrdocuing multi-threading to the language! As of June 2020, there doesn’t seem to be any compiler support according to the wiki page.
So I had to roll my own real quick:
//
// Synchronization Object similar to std::mutex except it allows multiple threads instead of just one
//
class Semaphore
{
public:
Semaphore(int val, int max) : maxVal(max), currVal(val) {}
inline void P() { Wait(); } // Edsger Dijkstra
inline void V() { Signal(); } // Edsger Dijkstra
void Wait();
void Signal();
private:
unsigned short currVal, maxVal; // 65,535 max threads assumed.
std::mutex mtx;
std::condition_variable cv;
};
void Semaphore::Wait()
{
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk, [&]() {return currVal > 0; });
--currVal;
return;
}
void Semaphore::Signal()
{
std::unique_lock<std::mutex> lk(mtx);
currVal = std::min<unsigned short>(currVal+1u, maxVal);
cv.notify_one();
}With two of the primary threads synchronized properly, let’s talk about the last bit of the multi-threading of VQEngine: Thread Pools.
Thread Pool
Implemented using the tutorial from Code Blacksmith on YouTube, the design uses std::packaged_task with std::future for waiting for a task completion.
I’ve given both Render and Update a pool of worker threads to further parallelize work. The number of worker threads are determined based on the number of available cores on the system.
void VQEngine::InitializeThreads()
{
// Initialize Sync Objects...
// Start Update & Render Threads...
// Initialize Worker Pools
const size_t HWThreads = ThreadPool::sHardwareThreadCount;
const size_t HWCores = HWThreads/2;
const size_t NumWorkers = HWCores - 2; // reserve 2 cores for (Update + Render) + Main threads
mUpdateWorkerThreads.Initialize(NumWorkers);
mRenderWorkerThreads.Initialize(NumWorkers);
}Two things to note here:
- Using ‘
NumPhysicalCores’ instead of ‘NumLogicalCores’ for scaling the threadpool.
This is to avoid over-threading and reduce SMT contention. - Leaving 2 cores for the 3 primary threads. I’ve settled with 2 cores here as the Main Thread is not expected to be as busy as the Update and Render Thread so they all can share two cores.
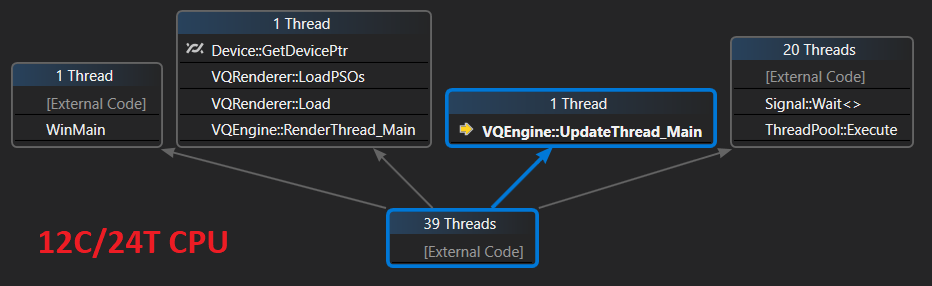
The workers can be used in a ‘fire and forget’ manner, as well as with a sync point utilizing a std::future object of return type of the given task. At this stage of the VQEngine, the worker threads are only used to simulate a second-long loading time with Sleep() so there currently is no real workload to test the Thread Pool API. I’m pretty sure I’ll need to adapt the interface to allow for certain sync point requirements or maybe add new capabilities such as dependent task dispatching.
I think the design serves a good base for now and I’ll keep profiling the threads as they start producing some real work.
Due to including plenty of templates and lambda functions, I’ve spared the implementation details of the Thread Pool. The YouTube video shows a step by step implementation, and my implementation, accompanied by plenty of comments, can be found in VQUtils/Threading.h and VQUtils/Threading.cpp files.
Wow, I’ve totally written a lot more than I originally planned. I think this is a good place to call this post the first of a series. The next one will be about the multi-monitor support, fullscreen modes and potentially HDR displays.
I may have left out some details to keep the length of the post relatively short. Feel free to leave comments should you have questions!
Cheers!